Building Tiny AI Tools: How I Integrated Slack, Jira, and AI to Create JiraGPT
An Introduction to Building Tiny AI Tools: My Experience Creating JiraGPT


Ever since OpenAI launched ChatGPT, my productivity has never been the same. I’ve always loved coding, but what I enjoy most is building—coding is just the means to make that happen.
In 2022, when I discovered ChatGPT, everything changed. Suddenly, I could ship projects faster and build MVPs more efficiently with the help of AI. It became a core part of my workflow, making development not only more productive but also more enjoyable. I use it for almost everything, and adapting to this new AI-driven approach has been both fun and transformative.
With this newfound efficiency, I wanted to take things further. My plan included experimenting with different AI tools to enhance my workflow and building my own AI-powered solutions. This led me to create TinyAI.Tools, a project where I develop and share AI tools that integrate seamlessly into everyday work. In this series, I’ll walk you through my journey, starting with how I built JiraGPT.
Who Am I?
I’ve been working as a software engineer for 10 years, primarily focused on backend development. Currently, I’m a hands-on engineering manager. As mentioned, I love building things and launching projects—it brings me joy to see something I built being useful for others.
Why “Tiny” AI Tools?
The word “tiny” isn’t meant to downplay the tool’s significance. It reflects that each tool is focused on solving a specific problem really well. There’s nothing I dislike more than exaggerated claims about what AI/LLMs can do. In my view, AI/LLMs work best when integrated into an already functional system to enhance it.
I’d like to emphasize that the tools I build are production-ready and secure. The goal isn’t just to experiment with AI/LLMs but also to solve real problems and build a sustainable business around them.
What Kind of AI Tools?
For now, I’m building AI wrappers—that is, leveraging off-the-shelf AI models (text, images, audio, video), whether open-source or proprietary. Some people criticize AI wrappers for not having a “moat”, and while that’s often true, I aim to provide more than just a simple interface to an LLM. After all, if you’re providing real value, who cares?
First Tool: JiraGPT
I initially built JiraGPT over a year ago, put it on hold for a few months, and recently rebuilt it with improvements. When I decided to work on the TinyAI.Tools project, I wanted to set up some groundwork and boilerplate for future tools, so I took the opportunity to rebuild JiraGPT with the features I envisioned. It may not have every feature yet, but the core functionality is there.
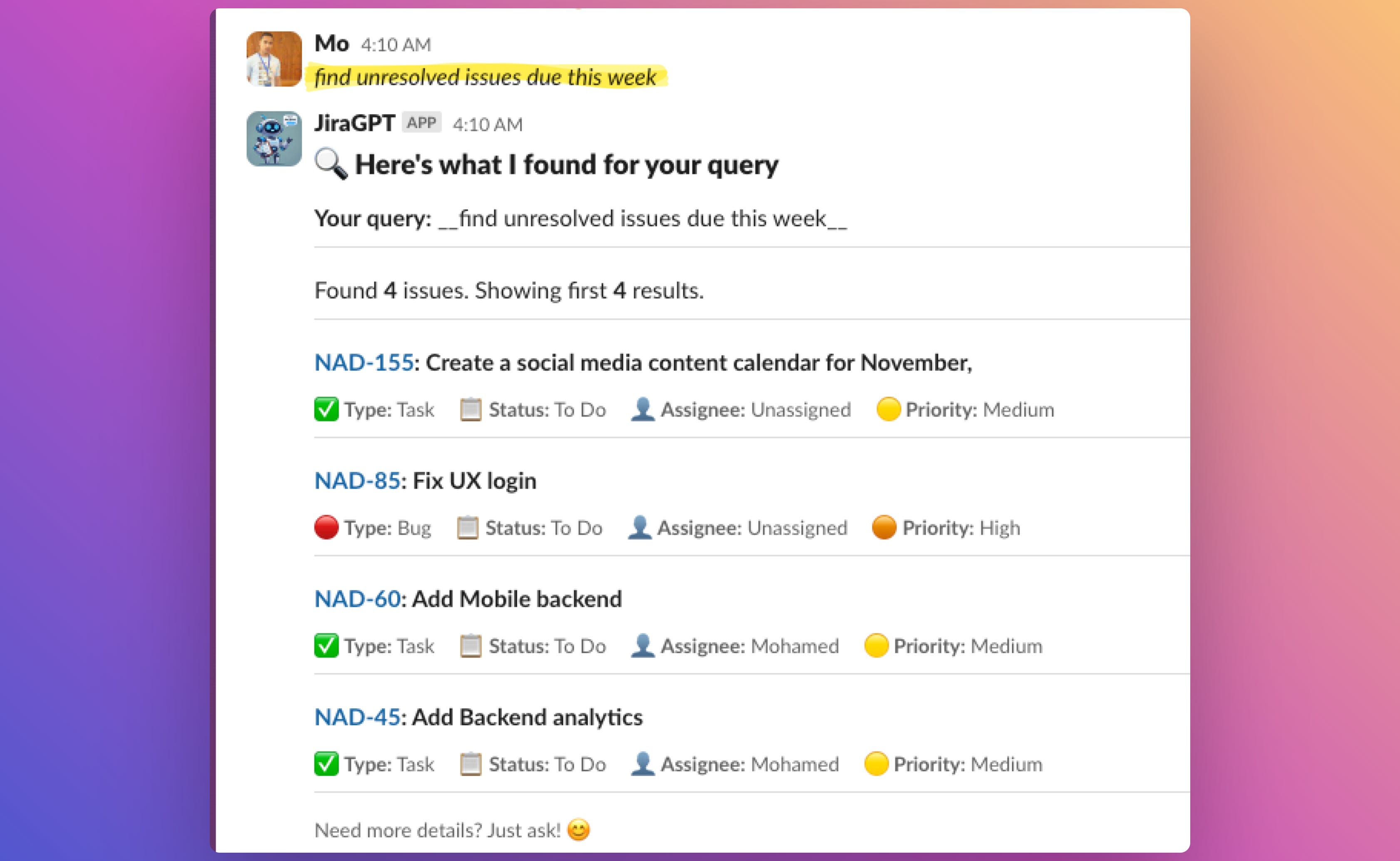
So, what is JiraGPT? It’s a Slack bot that allows you to search Jira issues using natural language directly from Slack. The idea came when I was a tech lead and often needed to search Jira without leaving Slack or memorizing complex JQL (Jira Query Language). Now, If you follow Atlassian (the company behind Jira), you might know they recently launched Atlassian AI, which lets you use natural language instead of JQL—but only within Jira, not Slack. That’s a key difference between their solution and JiraGPT. The grand vision for JiraGPT goes beyond searching; it aims to help you manage your Jira projects.
How JiraGPT Works
Once you connect your Jira instance (with read-only permissions) and install the Slack app, you can DM JiraGPT with queries like “find all in-progress stories that haven't been updated in 2 weeks”, and the bot will fetch the relevant Jira issue. Behind the scenes, the app converts your natural language query into JQL and calls the Jira REST API. Currently, JiraGPT does not store your Jira tickets, issues, or comments, which reduces data privacy concerns. For now, the app only requests permissions needed to fetch and store metadata, like project statuses, team member names, and custom fields, to help generate more accurate JQL.
How JiraGPT Works Behind the Scenes
This part gets a bit technical, but it should be understandable even if you work with a different tech stack. I use Python, Django, PostgreSQL, Celery, and Redis for background jobs, and TailwindCSS for styling and OpenAI GPT API. I won’t go into standard features like login or signup; instead, I’ll focus on how Slack, LLMs, and Jira are integrated.
When a user creates an account, they go through a two-step onboarding process. First, they connect their Jira instance. We use OAuth 2.0 for authentication and authorization, implementing the principle of least privilege by only requesting `read:jira-work` and `read:jira-user` permissions to call the search-by-JQL endpoint. The second step is to install the Slack bot. Once both steps are completed, JiraGPT initiates a DM with a greeting and usage examples.
Securing these connections is critical, and we follow best practices for authentication and authorization for both platforms. It’s also worth noting that we don’t store any of the messages exchanged between you and JiraGPT.
Fetching Your Project Metadata
For JiraGPT to generate accurate JQL and provide precise search results, it stores some metadata, like statuses, team member display names, and custom field names. Fetching and cleaning this data can be slow, so we use Celery to handle it in the background after the initial Jira connection. Metadata may change over time (e.g., new statuses or team members), so an hourly cron job updates this data regularly.
A Typical User Flow
Let’s walk through a typical user flow. You send a message to JiraGPT in Slack, such as “Show me high-priority tickets created in the past week” The system cleans and validates the query, then passes it to a service called JQLBuilder, which converts it into a valid JQL string. I use OpenAI’s structured output feature to ensure consistent results. Here’s what the service class looks like:
class JQLBuilder:
"""Build JQL queries from natural language queries."""
def __init__(self) -> None:
self.connection = connection
self.client = openai.OpenAI(api_key=settings.OPENAI_API_KEY)
self.project_metadata = <project metadata>
def build_jql(self, user_query: str) -> str:
"""Build a JQL query from a natural language query."""
# Basic sanitization
user_query = user_query.strip().lower()
prompt = JQL_BUILDER_PROMPT.format(project_metadata=self.project_metadata, user_query=user_query)
response = self.client.beta.chat.completions.parse(
model="gpt-4o-mini-2024-07-18",
messages=[{"role": "user", "content": prompt}],
response_format=JQLBuilderResponse
)
return response.choices[0].message.parsed.jql_query
class JQLBuilderResponse(BaseModel):
"""Response from the JQL builder."""
jql_query: strAnd here’s the prompt:
JQL_BUILDER_PROMPT = """
You are an expert Jira Query Language (JQL) builder. Your task is to convert natural language queries into accurate JQL queries based on the provided project metadata.
Project Metadata:
{project_metadata}
User Query: {user_query}
Guidelines:
1. Use the exact field names, statuses, priorities, and team member names as provided in the metadata.
2. For text fields, use ~ for contains searches and = for exact matches.
3. Use appropriate operators (AND, OR, NOT) to combine multiple conditions.
4. If the user query mentions a date, use appropriate date functions (startOfDay(), endOfDay(), startOfWeek(), etc.).
5. If the query is about a specific team member, use the 'assignee' field.
6. For custom fields, use cf[ID] syntax, where ID is the custom field id provided in the metadata.
7. Always include 'project = project_key' in your query unless the user specifically asks for issues across multiple projects.
8. If the user query is vague, make reasonable assumptions based on common Jira use cases.
9. If a mentioned field or value doesn't exist in the metadata, use the closest match or omit it if there's no suitable alternative.
If you cannot generate a valid JQL query, return an empty string ("") for the JQL Query
Remember, your goal is to create a JQL query that best represents the user's intent while adhering to the specific metadata of the project.
"""Once the user’s query is parsed into JQL, we pass it to Jira’s search-by-JQL API, format the response, and send the results back to the user.
Wrapping Up
And that’s basically how you can build a tool that searches Jira using natural language. To create something like JiraGPT, you need project metadata, a reliable LLM with structured outputs, and a seamless user interface—such as a Slack bot.
While the current approach focuses on generating JQL dynamically, there is an alternative strategy: you could index all project tickets, comments, and metadata into a vector database and use Retrieval-Augmented Generation (RAG) for searches. However, this method can be overkill for the feature’s current scope.
Keep in mind that this implementation has some limitations and room for improvement. I have a few ideas for enhancements but wanted to release this as a solid MVP with the core feature intact. Future updates will include relevant and meaningful additions only.
This project was an exciting way to explore practical applications of AI, especially in enhancing productivity tools. It showed me how AI could integrate seamlessly into existing workflows to solve specific pain points without unnecessary complexity.
I’d love to hear your feedback. Did you find the concept of building AI-powered integrations like JiraGPT useful? Are there aspects you’d like to see expanded or discussed in future posts? Let me know what you think!
Also, If this sounds interesting, I invite you to try out JiraGPT and see how it can streamline your workflow! And if you want to follow along as I build more AI tools and share insights from the journey, don’t forget to subscribe to my newsletter for more content like this!